Parsing Example
From String:
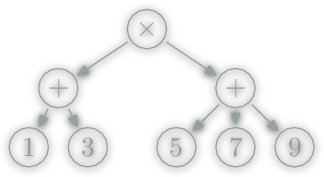
(1+3)*(1+5+9)To data structure:
Latin pars (ōrātiōnis), meaning part (of speech).
Complexity:
| Method | Typical Example | Output Data Structure |
|---|---|---|
| Splitting | CSV | Array, Map |
| Regexp | + Fixed Layout Tree | |
| Parser | Programming language | + Most Data Structure |
In Haskell Parser are really easy to use.
Generally:
From String:
(1+3)*(1+5+9)To data structure:
Parsec lets you construct parsers by combining high-order Combinators to create larger expressions.
Combinator parsers are written and used within the same programming language as the rest of the program.
The parsers are first-class citizens of the languages [...]"
In reality there are many choices:
| attoparsec | fast |
| Bytestring-lexing | fast |
| Parsec 3 | powerful, nice error reporting |
spaces are meaningful
f x -- ⇔ f(x) in C-like languages
f x y -- ⇔ f(x,y)Don't mind strange operators (<*>, <$>).
Consider them like separators, typically commas.
They are just here to deal with types.
Informally:
toto <$> x <*> y <*> z
-- ⇔ toto x y z
-- ⇔ toto(x,y,z) in C-like languageswhitespaces = many (oneOf "\t ")
number = many1 digit
symbol = oneOf "!#$%&|*+-/:<=>?@^_~"" \t " -- whitespaces on " \t "
"" -- whitespaces on "32"
"32" -- number on "32"
-- number on " \t 32 "
"number" (line 1, column 1):
unexpected " "
expecting digitdata IP = IP Word8 Word8 Word8 Word8
ip = IP <$>
number <* char '.' <*>
number <* char '.' <*>
number <* char '.' <*>
number
number = do
x <- read <$> many1 digit
guard (0 <= x && x < 256)
return (fromIntegral x)# remark: 888.999.999.999 is accepted
\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b
# exact but difficult to read
\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}
(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\bAlso, regexp are unityped by nature.
number :: Parser String
number = many1 digit
number' :: Parser Int
number' = do
-- digitString :: String
digitString <- many1 digit
return (read digitString)"32" :: [Char] -- number on "32"
32 :: Int -- number' on "32"s = (do
a <- string "a"
mid <- s
b <- string "b"
return (a ++ mid ++ b)
<|> string """" -- s on ""
"aaabbb" -- s on "aaabbb"
"aabb" -- s on "aabbb"
-- s on "aaabb"
S (line1 1, column 4):
unexpected end of input
expecting "b"s = concat3 <$> string "a" <*> s <*> char "b"
<|> string ""
where
concat3 x y z = x ++ y ++ zdata IP = IP Int Int Int Int
parseIP = IP <$>
number <* char '.' <*>
number <* char '.' <*>
number <* char '.' <*>
number
monadicParseIP = do
d1 <- number
char '.'
d2 <- number
char '.'
d3 <- number
char '.'
d4 <- number
return (IP d1 d2 d3 d4)number :: Parser Int
number = do
x <- read <$> many1 digit
guard (0 <= x && x < 256) <?>
"Number between 0 and 255 (here " ++ show x ++ ")"
return (fromIntegral x)>>> test parseIP "parseIP" "823.32.80.113"
"parseIP" (line 1, column 4):
unexpected "."
expecting digit or Number between 0 and 255 (here 823)(<?>)Time to do something cool
Let's write a minimal DSL
try tries to parse and backtracks if it fails.
(<||>) parser1 parser2 = try parser1 <|> parser2lexeme, just skip spaces.
lexeme parser = whitespaces *> parser <* whitespacesWrite Yourself a Scheme in 48 hours
Remember from text to data structure. Our data structure:
data LispVal = Atom String
| List [LispVal]
| DottedList [LispVal] LispVal
| Number Integer
| String String
| Bool BoolparseString :: Parser LispVal
parseString = do
char '"'
x <- many (noneOf "\"")
char '"'
return (String x)-- parseString on '"toto"'
(String "toto") :: LispVal
-- parseString on '" hello"'
(String " hello") :: LispValsymbol :: Parser Char
symbol = oneOf "!#$%&|*+-/:<=>?@^_~"
parseAtom :: Parser LispVal
parseAtom = do
first <- letter <|> symbol
rest <- many (letter <|> digit <|> symbol)
let atom = first:rest
return $ case atom of
"#t" -> Bool True
"#f" -> Bool False
_ -> Atom atomparseAtom-- parseAtom on '#t'
(Bool True) :: LispVal
-- parseAtom on '#f'
(Bool False) :: LispVal
-- parseAtom on 'some-atom'
(Atom "some-atom") :: LispValparseNumber :: Parser LispVal
parseNumber = Number . read <$> many1 digit-- parseNumber on '18'
Number 18 :: LispVal
-- parseNumber on '188930992344321234'
Number 188930992344321234 :: LispValparseExpr :: Parser LispVal
parseExpr = parseAtom
<||> parseString
<||> parseNumber-- parseExpr on '188930992344321234'
Number 188930992344321234 :: LispVal
-- parseExpr on '#t'
Bool True :: LispVal
-- parseExpr on 'just-some-word'
Atom "just-some-word" :: LispVal
-- parseExpr on '%-symbol-start'
Atom "%-symbol-start" :: LispVal
-- parseExpr on '"a String"'
String "a String" :: LispValparseList :: Parser LispVal
parseList = List <$>
(char '(' *> sepBy parseExpr' spaces <* char ')' )
parseExpr' :: Parser LispVal
parseExpr' = parseAtom
<||> parseString
<||> parseNumber
<||> parseList-- parseExpr' on '(foo (bar baz))'
List [Atom "foo",List [Atom "bar",Atom "baz"]] :: LispVal
-- parseExpr' on '(foo (bar)'
"parseExpr'" (line 1, column 11):
unexpected end of input
expecting white space, letter, "\"", digit, "(" or ")"
-- parseExpr' on '(((foo)) bar)'
List [List [List [Atom "foo"]],Atom "bar"] :: LispValSo Parser are more powerful than regular expression.
Parsec make it very easy to use.
Easy to read and to manipulate.
Notice how you could use parser as any other object in Haskell. You could mapM them for example.
Any question?
/
#